Medallion Architecture Data Flow
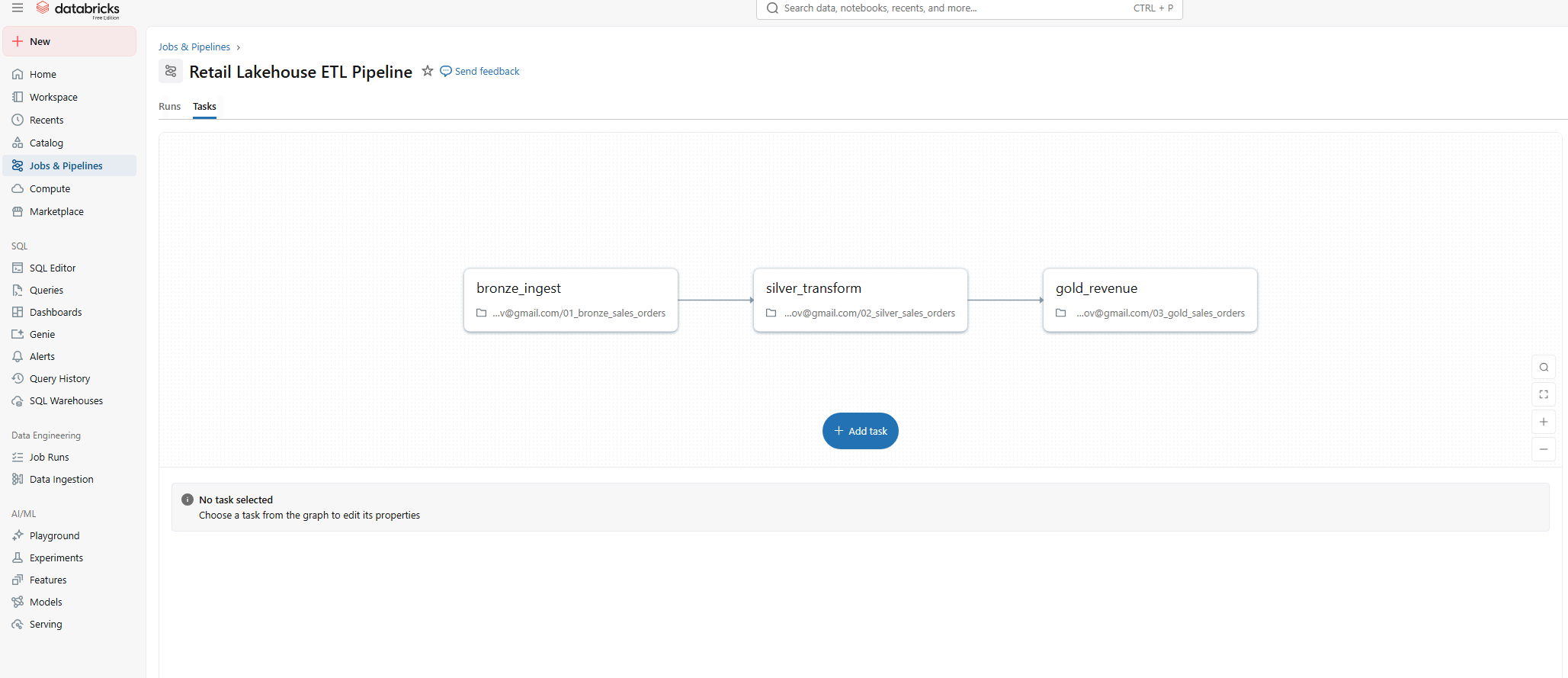
Live visualisation of the Delta Lake pipeline topology.
Data Engineering & BI
Time series forecasting to support planning, inventory optimisation, and executive decision-making.
A production-grade Lakehouse architecture on Databricks. Transforming raw chaotic logs into trusted Gold-level business intelligence assets.
Supply Chain Optimisation
Processing 10GB+ of daily transaction logs into a query-ready Delta Lake. Implemented a Medallion Architecture (Bronze -> Silver -> Gold) to ensure data quality and auditability for downstream BI teams.
Sales reports took 4 days to generate due to manual CSV mashing. Data inconsistencies between regional teams led to "truth wars" in executive meetings.
Designed a Spark-based ETL pipeline using Databricks Jobs. Enforced schema validation and automated quality checks at every layer of the Medallion architecture.
Bronze Layer
Silver Layer
Gold Layer
The pipeline is orchestrated using Databricks Jobs, with each medallion layer executed as a discrete, dependency-driven task. This approach ensures reliability, observability, and repeatability while enabling easy scheduling and monitoring.
Each task in the Databricks Job represents a logical stage in the data lifecycle, allowing failures to be isolated, monitored, and rerun independently without impacting downstream consumers.
Live visualisation of the Delta Lake pipeline topology.
Example of a Gold-layer transformation using PySpark Window functions to generate feature-rich datasets for the forecasting model. This logic runs incrementally on Databricks clusters.
from pyspark.sql import Window
import pyspark.sql.functions as F
def generate_gold_features(silver_df):
"""
Transforms clean Silver data into Gold-level features for forecasting.
Calculates rolling averages and week-over-week growth metrics.
"""
# 1. Define window for 7-day rolling metrics per region
window_7d = Window.partitionBy("region_id").orderBy("transaction_date").rowsBetween(-6, 0)
# 2. Key Business Metrics Calculation
gold_df = silver_df.withColumn(
"rolling_7d_revenue",
F.avg("daily_revenue").over(window_7d)
).withColumn(
"transaction_volume_momentum",
F.count("transaction_id").over(window_7d) / 7
).withColumn(
"is_holiday_surge",
F.when(F.col("daily_revenue") > (F.col("rolling_7d_revenue") * 1.5), 1).otherwise(0)
)
# 3. Write to Delta Lake with Schema Enforcement and Optimisation
(gold_df.write
.format("delta")
.mode("overwrite")
.option("mergeSchema", "true")
.saveAsTable("gold.sales_features_weekly")
)
return gold_dfThe Gold layer is structured to support time series forecasting by aggregating sales at consistent time intervals, enabling the application of classical forecasting models and machine learning approaches with minimal additional preparation.
Implemented Unity Catalog concepts for access control. Data quality expectations (e.g., "price > 0") are enforced before promotion to the Silver layer.
This project demonstrates the ability to design and implement a scalable data foundation that bridges raw operational data and advanced analytics. It highlights practical data engineering skills while directly supporting sales forecasting and executive-level reporting use cases.
Rather than focusing solely on forecasting models, this project demonstrates how reliable predictions depend on robust data foundations. By combining Databricks job orchestration with a layered data architecture, the solution mirrors real-world enterprise data platforms used to support forecasting, planning, and strategic decision-making.
Complete source code, documentation, and example notebooks available on GitHub